14 Sept 2012 (Friday) StartJG 總結
I totally forget my daily blog, until Sunday.
I guess I should write some of them in advance and schedule them. My bad
其實我應該趁我還沒有忘記的時候回顧一下我 StartJG 旳所學
總結一下
首先是完成了 Intel 的一個推廣網站
使用的技術是 python(Django)+PGSQL
Django 給我的感覺是完整的,功能齊全的CMS
但在 Model 的設定上需要小心
而python 作為一個web app 語言在方便性上比PHP有不足的地方
而且設定 apache 也比較複雜
除非是非常複雜的web app,否則我看不到不使用php 的理由
但不反感
而PGSQL 更加只是接觸到皮毛,談不上有任何有意義的感想
但我一直想試試 PGSQL 的 load balance/master slave的
而其他的小project 包括 Android app, instagram API, Mail tester, Jenkins, BDD, TDD, Agile, Fabric 等等
從 PHP, Java, Python 都有
而最有用的是對 python virtual environment 的認識
Fabric 的使用, Continuous Integration 的有關知識等
我應該要寫寫我使用 Fabric 的心得的
當然還有萬惡的 timesheets
試過 standing desk 的好/壞處
試過上環午飯時間的擠逼
Classicifed 的咖啡等等
最後,還有下定決心自立門戶的勇氣
(文為16日後補)
13 Sept 2012 AJAX file upload
Ajax upload file is still pain in the ass.
I have tested
http://blueimp.github.com/jQuery-File-Upload/
https://github.com/valums/file-uploader
I need a uploader that is triggered by JS (not after pick the file)
And it is very painful
callbacks, documentation, examples
By using XHR request but not iframe,
server side cannot use $_FILES, need sth like stream_copy_to_stream()
cannot send data with other parameters, like custom ID, title etc
WTF
And i need to build much more extra logic after saving the file,
like rename the file to hash (prevent hot linking)
save file related information to DB, which the example class do not provides...
JUST FOR A SIMPLE AJAX FILE UPLOAD.
I gave up.
30 blog posts in coming 30 days!
Long story short, I am a full time freelancer now.
So I can commit more time to this blog
and I am going to write one blog every day, until 11th Oct 2012.
I will blog my day, my readings, tech tips if i encounter etc etc.
This experiment had been done with some bloggers I had been follow
and although it seems though, most of them gain sth down the road
so best wishes!
And more importantly, I am a full time freelancer now.
Please refer and freelance/Startup!
Today I touch up this blog's css,
especially on responsive css and such,
view this blog on mobile should be nicer to your eyes
Try it out!
Also as I am writing this in a coffee shop,
I am thinking whether I should come here every day,
or just stay home.
coffee shop cost money everyday,
while stay at home would be easy to lost focus.
Any suggestions?
photo from mutednarayan
Android Multiple Async tasks
有 d android list view performance tips
http://lucasr.org/2012/04/05/performance-tips-for-androids-listview/
特別提一下 executeOnExecutor
aynctask 係一個一個 download
只要由 new AsyncTask 改為 executeOnExecutor 就可以同時下載
下載大量圖片的時候一定要使用.
話說我玩既 language 越黎越多....
譯文:reddit 的七個可擴展性秘密
前言:因為最近在做 Android 的東西
但還沒有什麼可以分享
又碰到 Obama 到訪 reddit 創下了單日單頁 2.7M PV (http://blog.reddit.com/2012/08/potus-iama-stats.html)
31/8月為止 5.2M PV
一分鐘 100K PV 的歷史記錄
便先譯文頂一下,看看2010年 reddit 的可擴展性 (scalability) 的文章 (兩年來系統沒有大改變)
原文:http://highscalability.com/blog/2010/5/17/7-lessons-learned-while-buildi...
(譯者:引文從略)
七個重點包括:
1. 多多崩潰
2. 業務分離
3. 開放式資料架構
4. 保持無狀態
5. memcache
6. 保存多餘的資料
7. 下線工作
1. 多多崩潰
這裡最重要是:自動重啟崩潰和有毒的服務
自建系統的其中一個問題是你需要自己維護。如果你的服務出了問題,那怕是凌晨半夜兩點,都要你自己解決。這是一個二十四小時都在拖你後腿的壓力。你去那兒都要帶你的電腦因為你知道任何人任何時候都會打你的電話告訴你又出現了問題。它會取走你的生活。
其中一個解決的方法是重啟死亡的或將死的進程。Reddit 使用 Supervise 來自動重啟程式。特別的監控程式會除掉使用過多內存,過多CPU,或無响應的進程。總之重啟就對了。當然你要讀一下LOG 找出源頭,但首先是你不會被壓力迫瘋。
2. 業務分離
這裡最重要是:將相似的進程和資料放到相同的伺服器
一個單體伺服器做太多的工作會令它帶來很多轉換的麻煩 (a lot of context switching between jobs)。試試令每一個資料庫伺服器送出相似的資料。也即是說全部索引都會被緩存,不會進出硬碟。保持相似的任何東西在一起。不使用 Python Threads,太慢了。它們將全部東西放到
不同的進程。服務(Services) 例如 Spam,縮圖,query 緩存都可以輕易放到專用的機器。而且你會發現你已經開始進程之間的傳送,便很容易繼續擴展。
3. 開放式資料庫結構 (schema)
這裡最重要是:不要擔心資料庫結構
大家都試過花很多時間擔心資料庫結構,保持整潔和 normalize。但你不應該擔心資料庫結構。修改資料庫結構是很花時間的,新加一列欄位到一千萬行的表會造成鎖定和根本不會完成。這些更新也會令複制備份變成痛苦的工作,會令你從新建立一個備份而且失去一日的備份。部署也一樣,你要同時更新你的程式和資料庫結構。
Reddit 保持一個“東西表” (thing table) 和“資料表” (data table)。站內的都是 Thing,用戶,連結,留言,子頁面等,此表保有共用的屬性,例如上下點數,類型,建立日期。資料表則有三列:ID,key,value。每一個屬性佔一行,一行標題,一行網址,作者,spam votes等。加入新屬性不需要擔心結構,不需要新的表或擔心部署的問題。更容易開發,部署,維護。但就失去了關連結構。沒有 join也即很容易打散資料到不同的伺服器。不需要擔心 foreign key 或如何分開資料。真的很好用。關連資料庫變了過去式。
4. 保持無狀態 (stateless)
最重要是每一個伺服器都可以處理全部種類的請求。擴展的時候有太多機器而不可以依賴它們自身的緩存。原先 Reddit 是會複制狀態到每一個機器的,但只是浪費內存。又不可以使用 memcached 因為需要緩存的東西太多。它們重寫了的 memcache 機制而不緩存狀態。這也令崩潰的伺服器不會做成大破壞。擴展時只需要加更多伺服器。
5. memcache
這裡最重要是:緩存全部東西
資料庫資料,會話(session),渲染的頁面,先前的計算結果,使用者用量限制,預先處理的頁面,全局鎖定。
Reddit 的 memcachedb 保有多於 postgres 的資料。它就像memcached 但存到硬碟。非常的快。同一組條件的查詢(query) 都放到 memcached。修改密碼的連結和相關資料放到緩存保存20分鐘。Captchas 也一樣。也緩存非永久的連結。
列表的計算,頁面都內嵌 memcached,緩存。
使用者用量限制使用 memcached + 期滿日期。這是其中一個方法擋攻擊。否則單一個用戶便可以影響系統穩定。所以 memcached 保有很多用戶和爬蟲的資料。用戶一秒之內重火請求的話會被踢走,一般的用戶不會點擊得如此密集。Google 爬蟲會用你給予的最快速度,所以系統不穩定的時候限制它便可以不影響用戶的情況下減少負荷。
Reddit 都是些列表,首頁,收件箱,留言頁。全部都是預先處理放到緩存。你拿到的列表都是來自緩存。連結,留言都緩存大約一百個不同的版本。例如,一個連結有兩個投票,緩存預渲染30秒,30秒之後便再預渲染,緩存。每一個 html 都來自緩存所以 CPU 沒有浪費它的時間。站慢了便增加緩存。
當資料庫都會變得脆弱,便使用 memcache 作為全局鎖。不是最好的方法但有效。
6. 保存多餘的資料
這裡最重要是:速度等於預處理然後緩存它
慢的站是完美的 normalize 資料庫,有需要才查詢,再渲染,就是每一個請求都太花時間。所以如果資料會以不同的方式呈現,例如首頁的連結,收件箱,個人頁面,緩存所有可能的方式。在有需要的時候即可使用。
每一個列表都有15個不同的排列方法,熱門,最新,最高,最舊,這個星期。當有人提交連結便會重新計算它對全部列表的影響。可能會有浪費,但總比慢好。浪費硬碟空間和內存總比用戶等待好。
7. 下線工作 (預處理)
這裡最重要是:做最小的工作然後告訴用戶已經完成了
如果你需要完成些事而用戶並非在等待你,將它放到序列。用戶投票,用戶的點數,還有其他。所以投票的過程是資料庫被通知了,序列了,序列知道有20更新事件。用戶返回的時候資料已經預處理了。
還有:預處理列表,取得縮圖,檢查作弊,移除 spam,處理獎勵,更新搜尋索引。都是無需用戶等待完成的。例如,檢查作弊變得日益重要了,Reddit 花了很多時間在用戶投票的時候檢查作弊。但 reddit 在背景處理,使用經驗沒有改變。
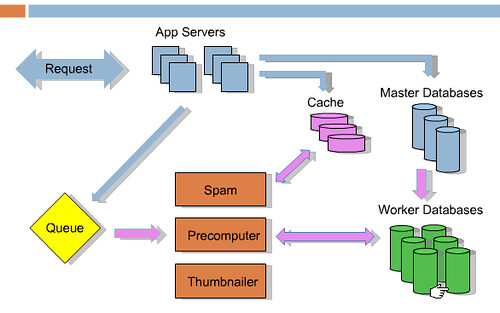
上圖藍色箭頭是收到新的請求,提交連結或投票進入緩存,資料庫和序列。然後返回用戶。其餘的都下線進行,粉紅色表示。Spam,預處理,讀取序列,處理序列,更新資料庫。使用 RabbitMQ 序列。
